
Hyperparameter Tuning and Model Selection
Posted on January 24, 2025 • 4 minutes • 702 words
Table of contents
Introduction
Hyperparameter tuning is process of finding best parameters for training model. It is like choosing right proportions of ingredients for cooking a recipe, correct proportions of spices, how much oil and how long it should cook.
What are Hyperparameters?
Hyperparameters are just combination of parameters, by using which we will get accurate and better model. They are defined before the training the model, these settings affect how the model will learn from the data.
Importance:
If you don’t tune hyperparameters correctly, the model may:
Underfit: The model is too simple and doesn’t capture patterns in the data.
Overfit: The model is too complex and memorizes the training data instead of generalizing.
Tuning hyperparameters helps balance these issues and improves accuracy.
Examples:
Learning Rate: Controls how fast or slow the model updates itself.
Number of Trees in a Random Forest: Affects how deep the model looks into the data.
Number of Hidden Layers in a Neural Network: Determines the model’s complexity.
Batch Size: The number of samples used at once during training.
Regularization Strength: Helps prevent overfitting by keeping the model simple.
But before we go and do hyperparameter tuning we must select our model.
Model Selection
Model is the process of choosing the best machine learning model for a given dataset and problem.
Key Factors in Model Selection:
What of kind of problem it is?
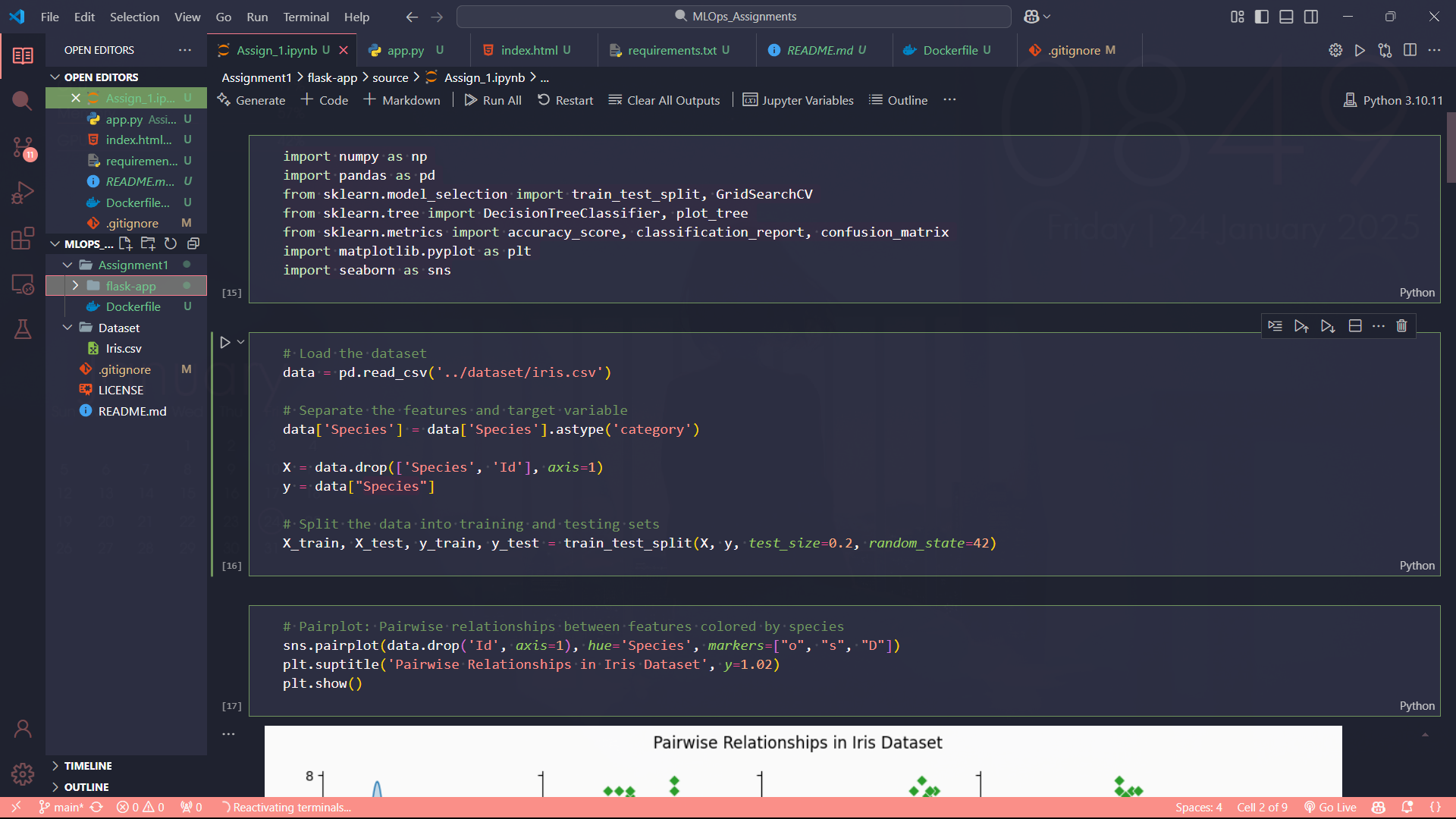
- Regression Problem: When we need predictions of continous numerical value based on input features. Examples are weather prediction, house prediction. Algorithms used linear regression, random forest, gradient boosting.
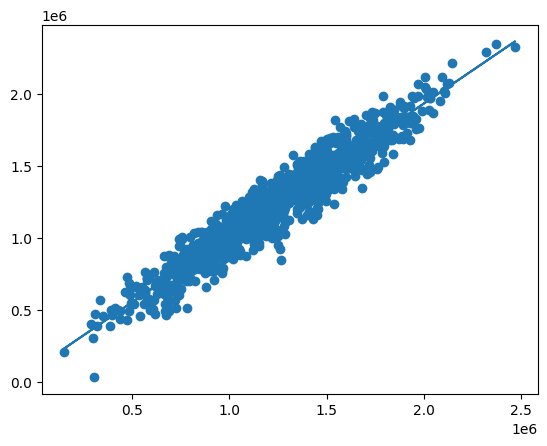 fig0: Linear Regression
fig0: Linear Regression- Classification: It is used where goal of it is to predict discrete labels. Examples are identifying letters in handwritten text, classifying news categories like gaming, politics. Algorithms used logistic regression, decision trees, neural networks.
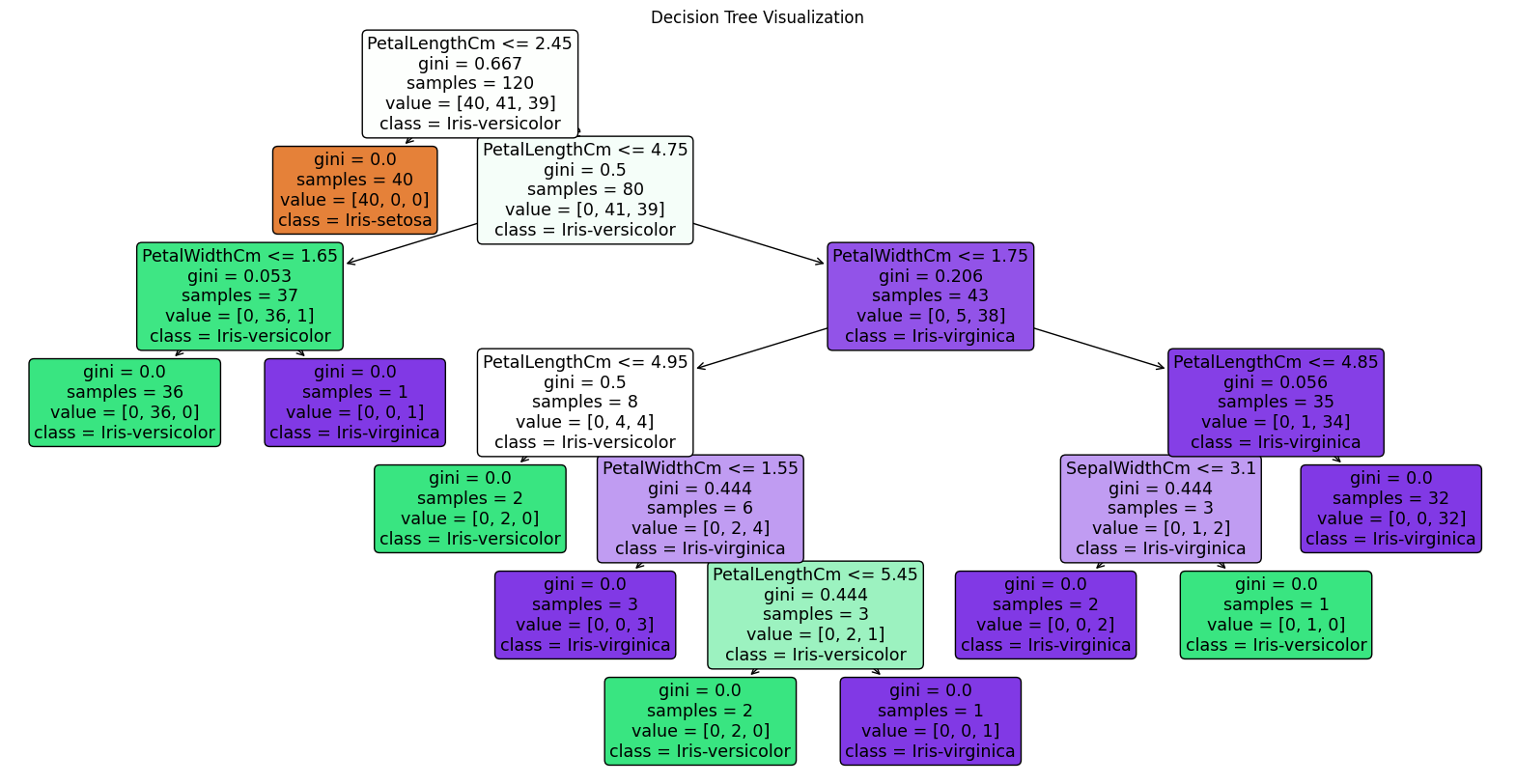 fig1: Decision Tree Classification
fig1: Decision Tree Classification- Clustering: When the goal is to group similar data points together without predefined labels. Examples are customer segementation based on their buying behavior, document clustering, anomaly detection. Algorithms used K-Means, DBSCAN, hierarchical clustering.
 fig2: K-Means Clustering
fig2: K-Means ClusteringComputation Resources Available:
Limited Resources: If you are limited on resources used algorithms which are less computationally expensive like support vector machines(SVM), decision trees.
High Resources: Used algorithms in deep learning to best better and accurate model.
With all that in mind let’s do hyperparameter tuning.
Methods of Hyperparameter Tuning
- Manual Tuning (Trial and Error)
The simplest approach is to experiment with different hyperparameters and observe the model’s performance. This works for small models but becomes time-consuming as the number of hyperparameters increases.
- Grid Search
In Grid Search, you define a list of possible values for each hyperparameter, and the computer tests every possible combination.
Example (Using Python’s Scikit-Learn):
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
param_grid = {
'n_estimators': [10, 50, 100],
'max_depth': [None, 10, 20]
}
model = RandomForestClassifier()
grid_search = GridSearchCV(model, param_grid, cv=5)
grid_search.fit(X_train, y_train)
print("Best Parameters:", grid_search.best_params_)
Pros: Finds the best combination from a predefined list.
Cons: Very slow if there are too many hyperparameters.
- Random Search
Instead of testing every combination, Random Search picks random values from a predefined range.
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
param_dist = {
'n_estimators': randint(10, 200),
'max_depth': randint(1, 20)
}
model = RandomForestClassifier()
random_search = RandomizedSearchCV(model, param_dist, n_iter=10, cv=5)
random_search.fit(X_train, y_train)
print("Best Parameters:", random_search.best_params_)
Pros: Faster than Grid Search.
Cons: Might miss the best combination.
- Bayesian Optimization
This method builds a mathematical model to predict which hyperparameter settings will work best. It uses fewer trials than Grid or Random Search.
import optuna
def objective(trial):
n_estimators = trial.suggest_int("n_estimators", 10, 200)
max_depth = trial.suggest_int("max_depth", 1, 20)
model = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth)
return cross_val_score(model, X_train, y_train, cv=5).mean()
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=20)
print("Best Parameters:", study.best_params_)
Pros: Efficient for complex models.
Cons: More difficult to implement.
Which Method Should You Use?
For small datasets: Grid Search is fine.
For large models: Random Search or Bayesian Optimization works better.
Conclusion
Hyperparameter tuning is like adjusting the ingredients in a recipe to get the perfect taste. It takes time, but when done right, it significantly improves model performance. Whether you’re testing different learning rates or tweaking the depth of a decision tree, tuning can help make your machine learning model more powerful and accurate.
References
- https://aws.amazon.com/what-is/hyperparameter-tuning
- https://en.wikipedia.org/wiki/Hyperparameter_optimization
- https://scikit-learn.org/1.5/modules/grid_search.html
- https://towardsdatascience.com/model-selection-a-guide-to-class-balancing-part-i-14b17003186f
- https://en.wikipedia.org/wiki/Model_selection
Thank You for Reading!